Statistical Natural Language Processing in Radiology Reports
This webpage is created to document and share our progress in Radiology NLP.

Summary of article
Text processing approach based on natural language processing (NLP) and machine learning to identify sentences that involve clinically important recommendation information in radiology reports
Existing methods
MedLEE
- Extracts and structures clinical information from radiology report text
- Translates clinical information to terms in a controlled vocabulary
- Translates clinical information accessed by further automated procedures
SAPPHIRE
- Matches text to concepts in the Unified Medical Language System (UMLS) Metathesaurus
- Indexes radiology reports automatically
- Develop clinical image repositories that can be used for patient care and medical education
- Note: One of the precursors to MetaMap
Lexicon Mediated Entropy Reduction (LEXIMER)
- Identifies reports that include clinically important findings and recommendations for subsequent action
- Black box approach
Pipeline
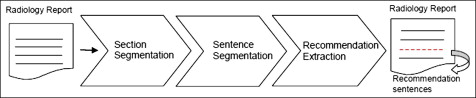
Section segmentation
- Divides radiology report into 11 main sections
- Classifier operates at line level instead of sentence level since content of clinical records tends to be fragmentary and list based.
Pre-processing step: Create list of sections by randomly selecting small subset of reports
First step post-processing: Section Segmentation
| Type | Features |
|---|---|
| Text features | isAllCaps, isTitleCaps, containsNumber, beginsWithNumber, numTokens, numPreBlanklines, numPostBlanklines, firstToken, secondToken, unigram |
| Tag features | prevTag, prevTwoTags, tagChainLength |
Second step post-processing: Section classification
| Type | Features |
|---|---|
| Header features | Same as Text features, only the header line is used |
| Body features | avgLineLength, numLines, docPosition, containsList, unigram |
| Tag features | prevTag, tagHistUnigram, tagChainLength |
Sentence segmentation
- Goal:
Recommendation Extraction
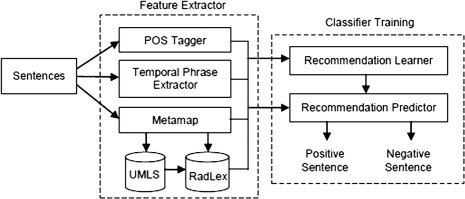
Creating feature vector
A feature vector is created based on the characteristics and content of the sentences in the report, and includes:
| Category | Feature Type | Type of variable | Dimension |
|---|---|---|---|
| Baseline (B) | unigram | string | num of words |
| Ngram (N) | bigram | string | num of bigrams |
| Ngram (N) | trigram | string | num of trigrams |
| Syntactic (S) | tense | categorical | num of tenses |
| Syntactic (S) | stemmedVerb | string | num unique stemmed verbs |
| Syntactic (S) | includesModalVerb | binary | num sentences |
| Syntactic (S) | includesTemporalPhrase | binary | num sentences |
| Knowledge (K) | UMLSConcept | binary | num UMLS concepts |
| Structural (St) | sectionType | binary | num section types |
Explanation of variables:
Classifier training
Model Selection
Feature set size and type selection (subset selection).
Problem: Model too sparse.
Goal: Select most predictive variables to incorporate in final model.
Steps:
- Code distinct features to create huge design matrix.
- Stepwise variable selection to select number of variables (N) for baseline (unigrams).
- Stepwise variable selection to select combination of features.
- Rank features using 5-fold cross validation using F-score.
Data imbalance experiments
Problem: Proportion of positive: negative sentences is very low (1:165).
Goal: to select a ratio of positive: negative sentences that gives the optimal recall, precision & f-score.
Steps:
- Create feature vector for each sentence.
- Train 165 classifiers, each with ratio of i:1 negative: positive sentences, i = 1 to 165. For training fold, all positive sentences are used, while negative sentences are randomly selected to give the ratio i:1 For test fold, all negative sentences are included (all 165 exp have same test set)
Error Analysis
- 5-fold cross validation (few positive sentences)
- Criteria used include: false positives, false negatives, precision, recall, F-score